A practical walkthrough · 22 screenshots · ~7 minutes to read
From an empty repo toa working brain.
A real run, captured frame by frame: create a fresh kluris brain, hand the first project to your
AI agent, curate the neurons it proposes one by one — approve, edit, or reject — open the MRI
visualization, ask the brain to review itself, and finally use it every day to ship features and
answer questions.
1 Create the brain2 Add the first project3 Explore with MRI4 Review the brain5 Use the brain
+
How a brain actually grows
Human and AI agent work together to create, restructure, and improve the brain.
Nothing is auto-saved. The agent surveys the project, drafts neurons, and shows them to you one by one. You read,
edit, accept, or reject — every entry is yours before it lands. Over time the brain reorganizes itself with your
approval: new lobes appear, old neurons get split or merged, synapses connect what belongs together. The result is
a knowledge base shaped by your judgment, written by both of you.
1
Phase 1 · One-time setup
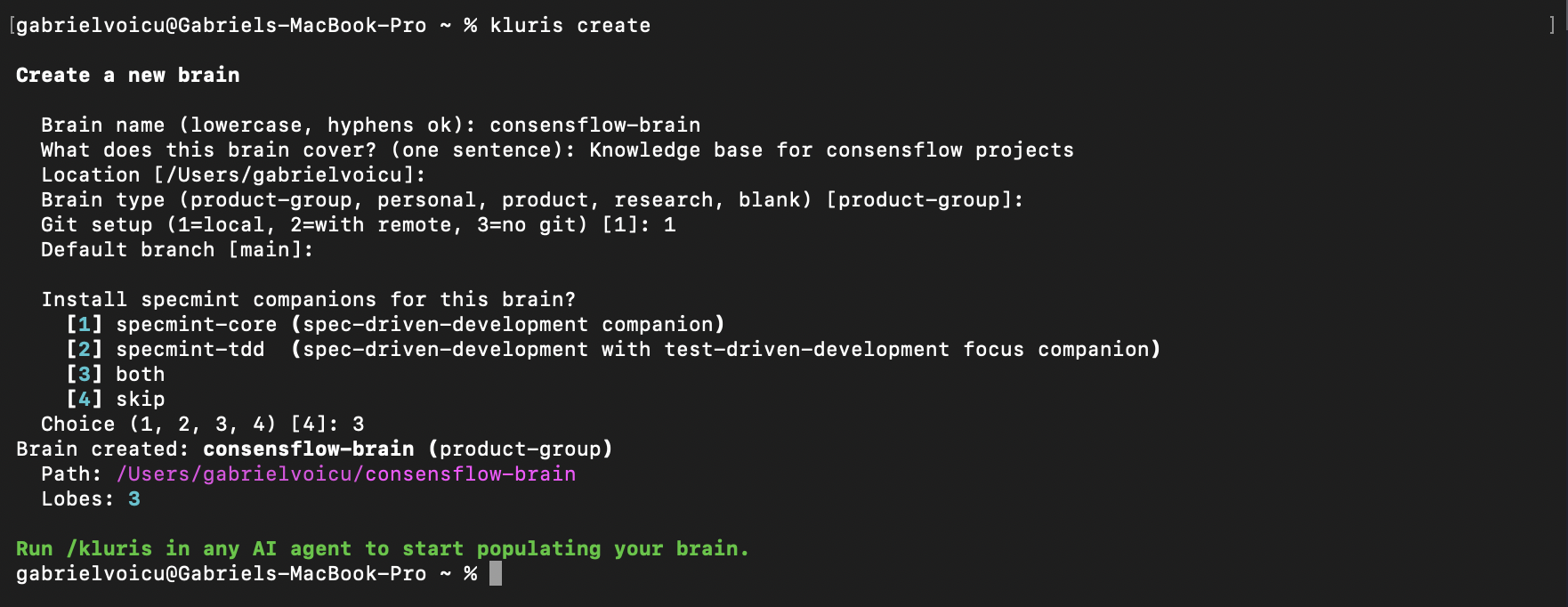
Create the brain.
One kluris create command, a few questions, optional specmint companions —
and you have an empty git-tracked brain ready to be taught. This step happens once per domain.
01 · kluris create — name, type, git setup, and the specmint companion picker
Before each project · Wire kluris in
Drop a pointer in CLAUDE.md and AGENTS.md.
Before you teach the brain anything about a project, drop a small pointer into the
project's CLAUDE.md and AGENTS.md so every coding agent that
lands in the repo knows the brain exists. The skill (and only the skill) reads and
writes the brain — never edit brain files by hand.
>/kluris-<brain> setup this projectSurveying CLAUDE.md and AGENTS.md...CLAUDE.md: missing — propose creating it
AGENTS.md: missing — propose creating it
Proposed ## Knowledge base section (same in both files):
──────────────────────────────────────## Knowledge base
Read and write to the **<brain>** brain through kluris
(never edit brain files by hand). Use the /kluris-<brain>
skill — search, learn, remember, create.
──────────────────────────────────────
[a]pprove [e]dit [s]kip: a✓ CLAUDE.md created
✓ AGENTS.md created (same ## Knowledge base block)
The same block goes in both files because not every coding agent reads
CLAUDE.md — Codex, OpenCode, Cursor, Windsurf, Cline, and
Gemini CLI read AGENTS.md. Re-run any time; if the pointer is
already there, the agent says so. If it's stale, it offers to reformulate.
2
Phase 2 · Repeats per project
Add the first project.
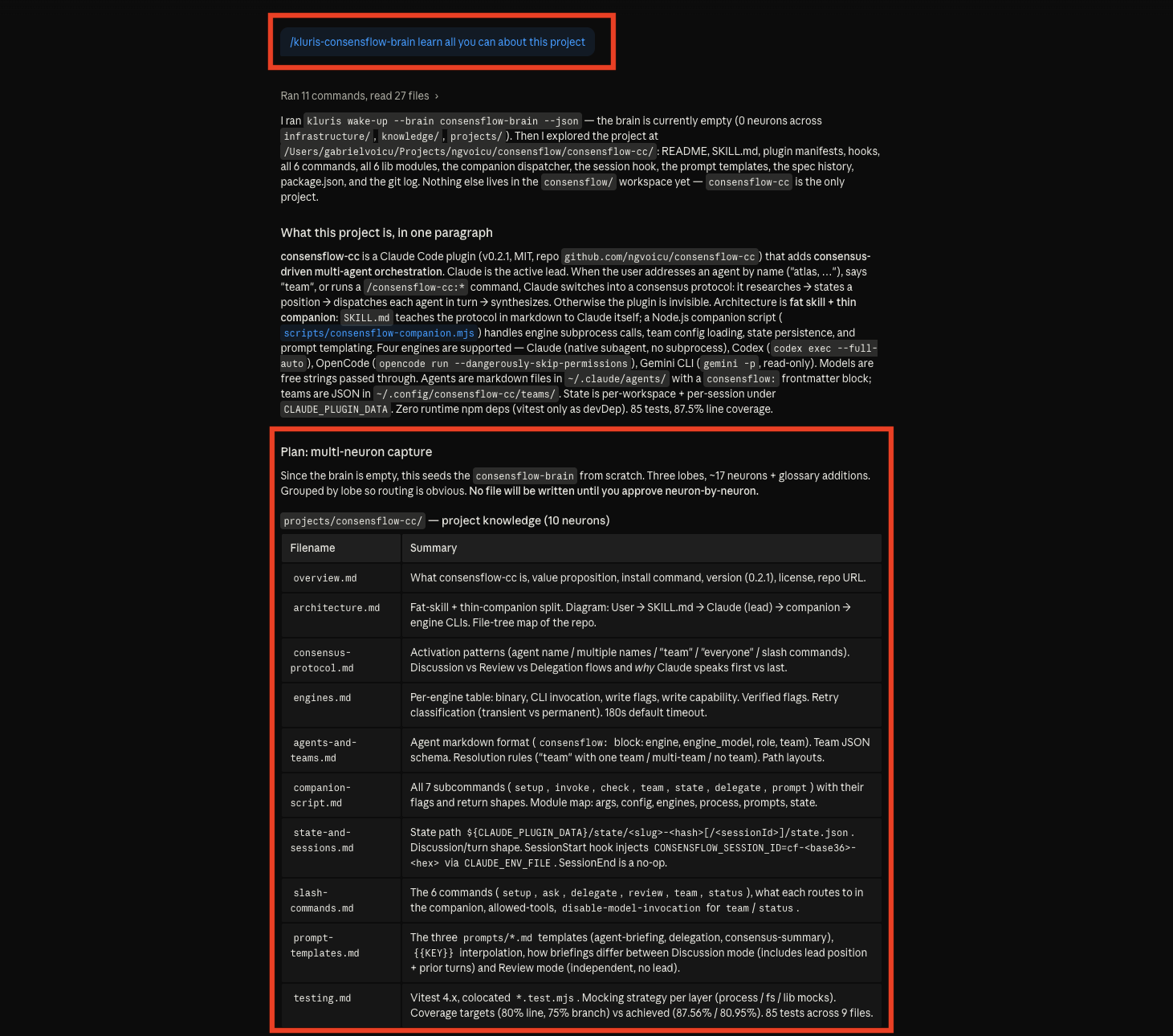
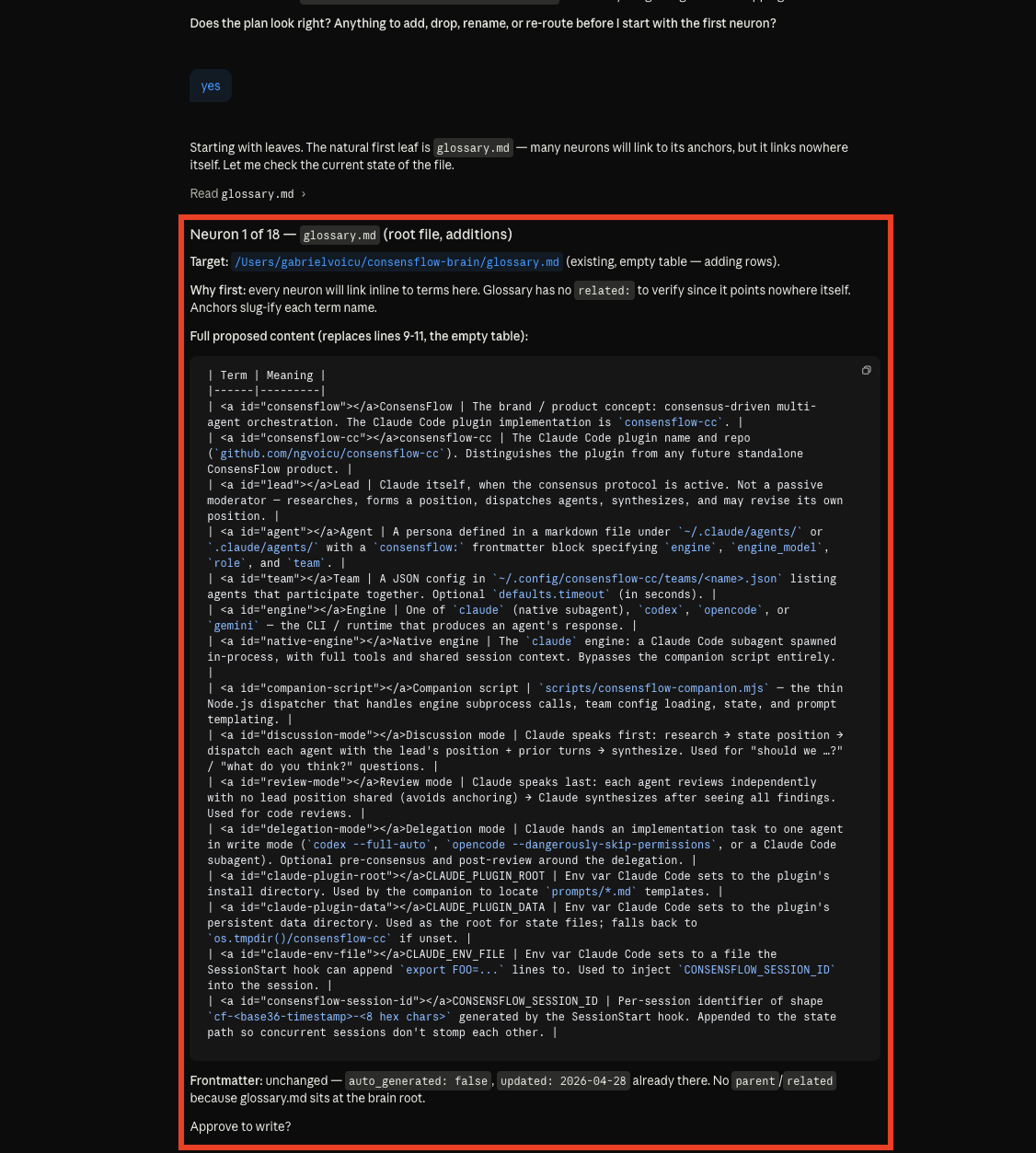
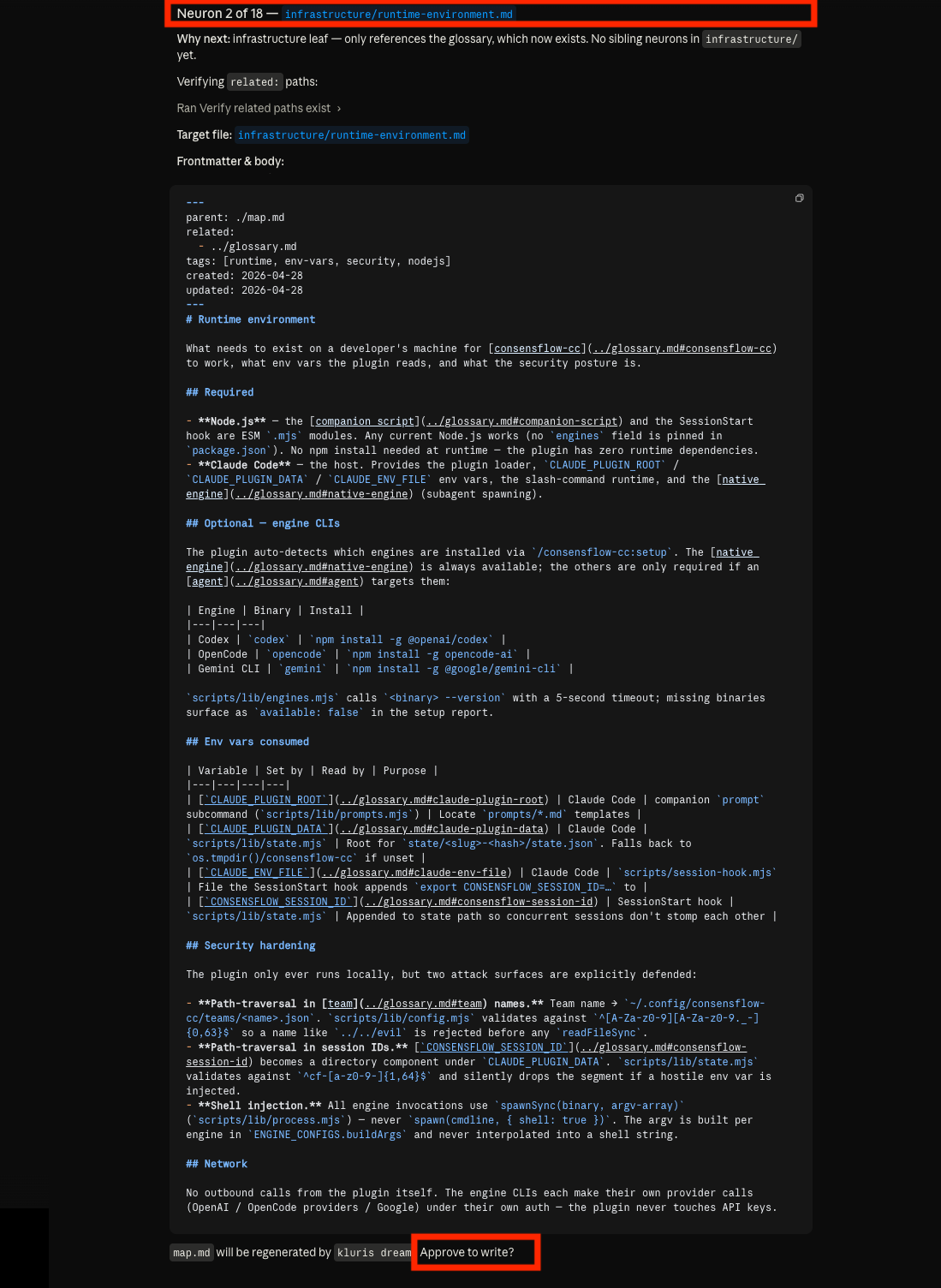
Open the project repo, ask the kluris-aware agent to study it, and the back-and-forth begins. The agent surveys the
code, plans neurons across lobes, then shows them one at a time for you to review — the file format, the body, every
decision. Nothing is committed without your approve.
02 · The agent reads the repo and proposes a capture plan — files surveyed, packages mapped, what's worth keeping
03 · Candidate neurons grouped by section — decisions, distribution, extensions — before anything is written
04 · Neuron 1 of 5 shown in full — frontmatter, body, security review — approve, edit, or reject before it lands
05 · Neuron 2 of 5 — same review flow, repeated for every proposed neuron until the queue is empty
3
Phase 3 · Repeats per project
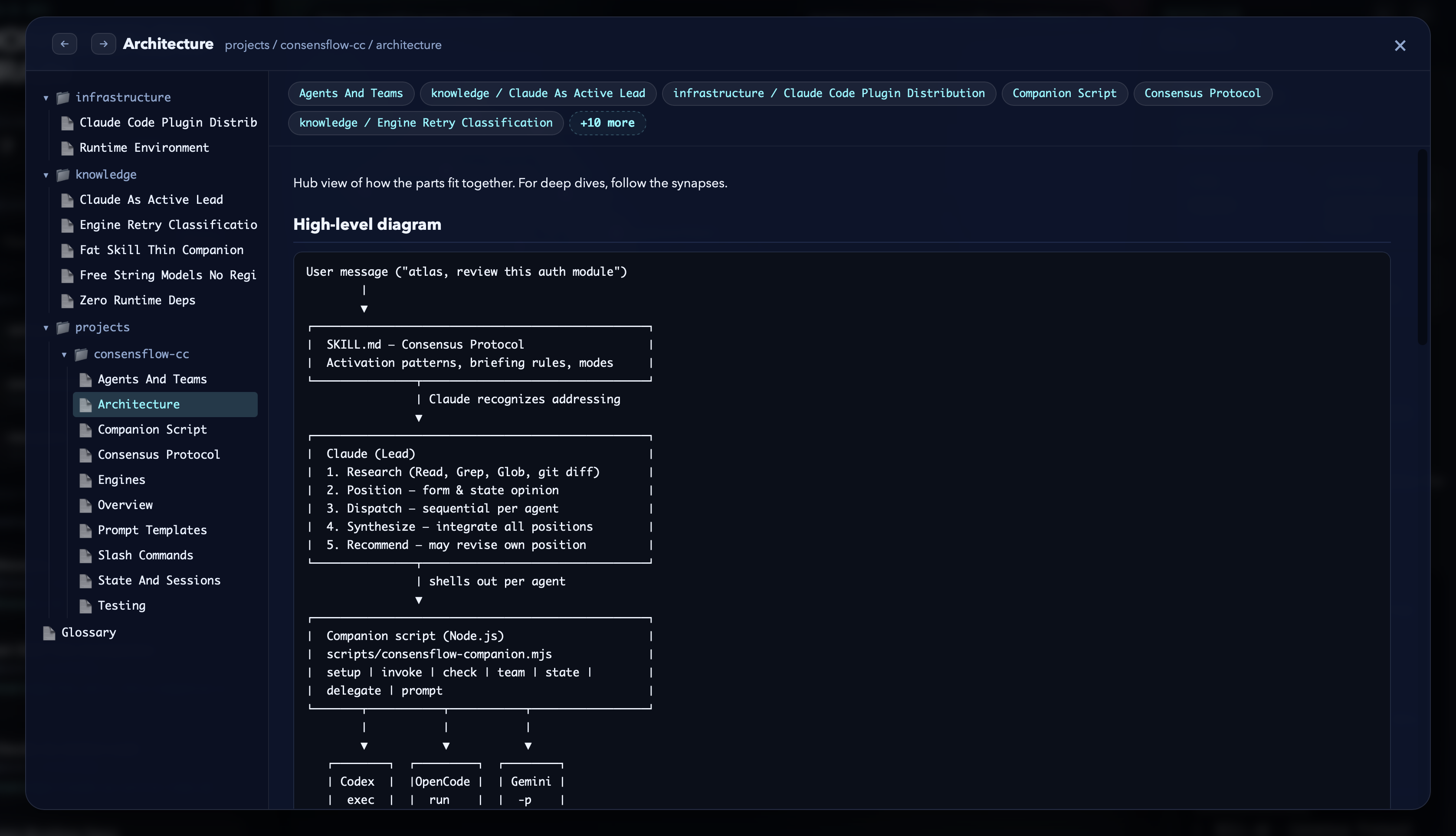
Explore it with the MRI.
Run kluris mri and the brain opens in your browser as a single-page graph.
Every lobe, every neuron, every synapse — pannable, searchable, shareable. Click a node to read it, expand the
synapses to see what touches it, follow the threads.
06 · kluris mri picks a brain and prints a clickable file:// URL — 23 nodes, 167 edges, opens offline
07 · The whole brain in one screen — left rail of lobes, center force-graph of neurons and synapses, right inspector with the selected neuron's metadata
08 · Click the Architecture neuron — its full body opens with breadcrumbs, related lobes, and the embedded high-level ASCII diagram
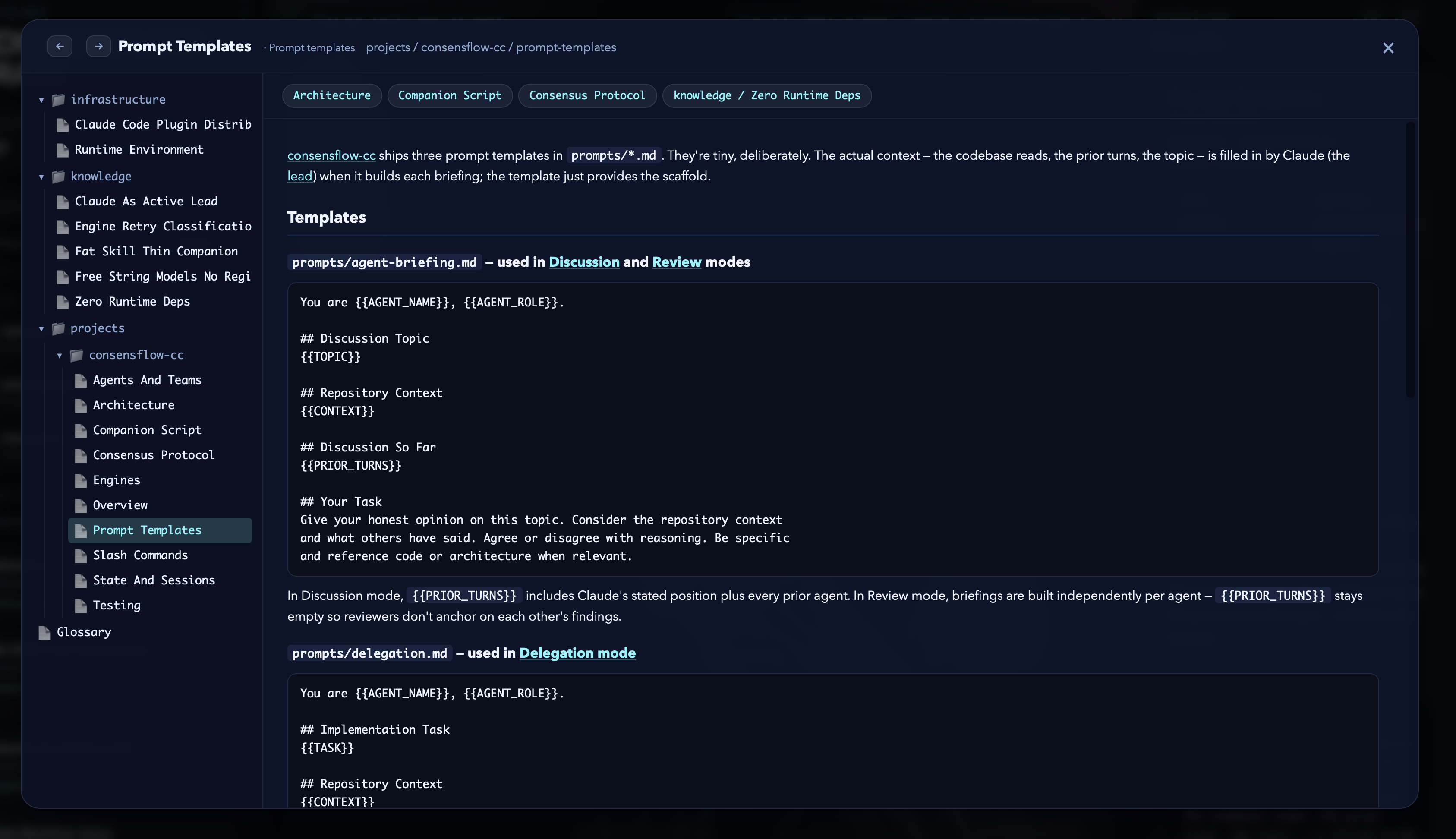
09 · Prompt templates are first-class neurons too — the actual templates that drive the agents, viewable side-by-side with code
Repeat to grow the brain
One brain per domain. Many projects per brain.
Phase 1 happens once. Phase 2 (add a project) and
Phase 3 (explore with the MRI) repeat for every other project in the same
domain — a sibling repo, a frontend that talks to the same backend, a deploy script, a shared library. Each one
teaches the brain a little more, the lobes fill out, the synapses multiply, and the MRI keeps showing you what
your team actually knows about that domain.
create →
add project →
MRI
·
add next project →
MRI
·
add next project →
MRI
·
…
4
Phase 4 · Periodic health check
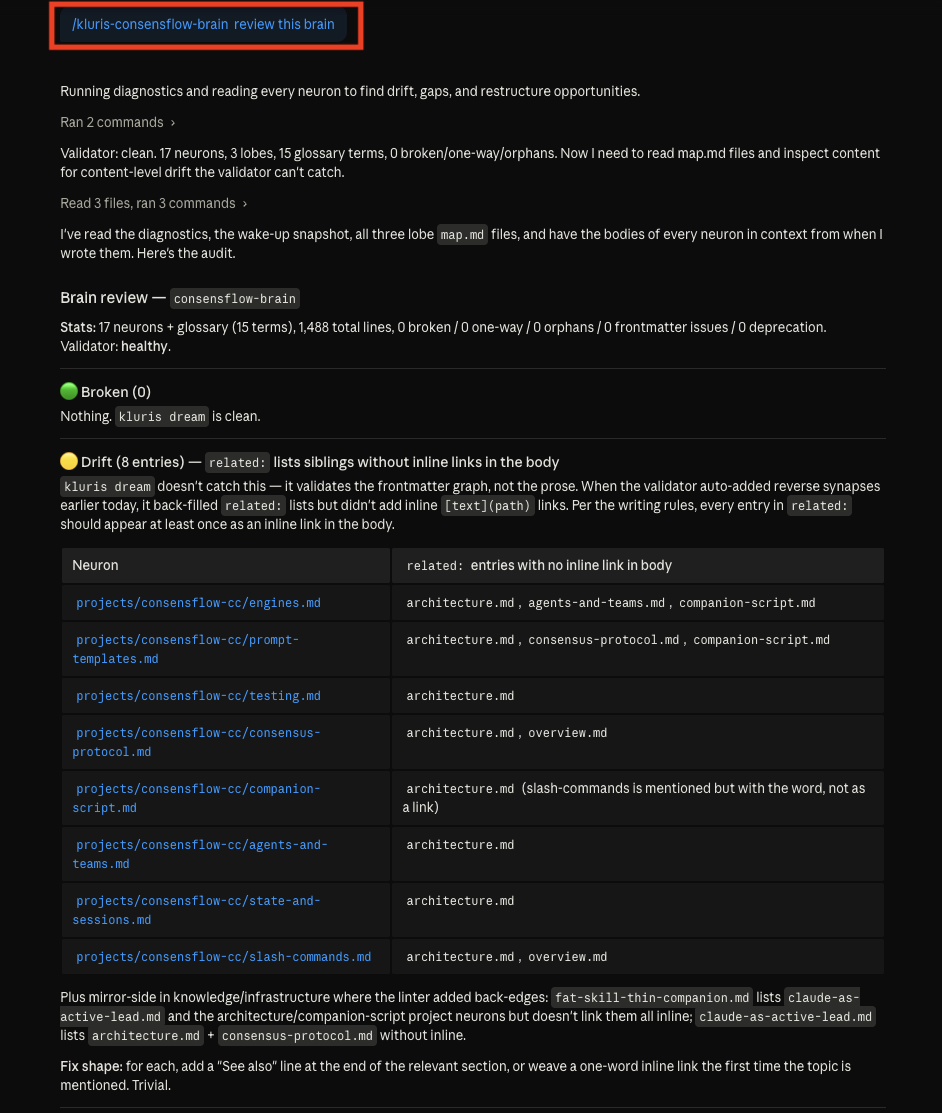
Let the brain review itself.
Once enough projects live in the brain, ask it to audit itself. The agent reads every neuron, looks for
gaps, contradictions, missing synapses, neurons that should be split or merged — and proposes a restructuring plan.
Same approval flow as before: you accept the changes you like, reject the rest. The brain stays clean as it grows.
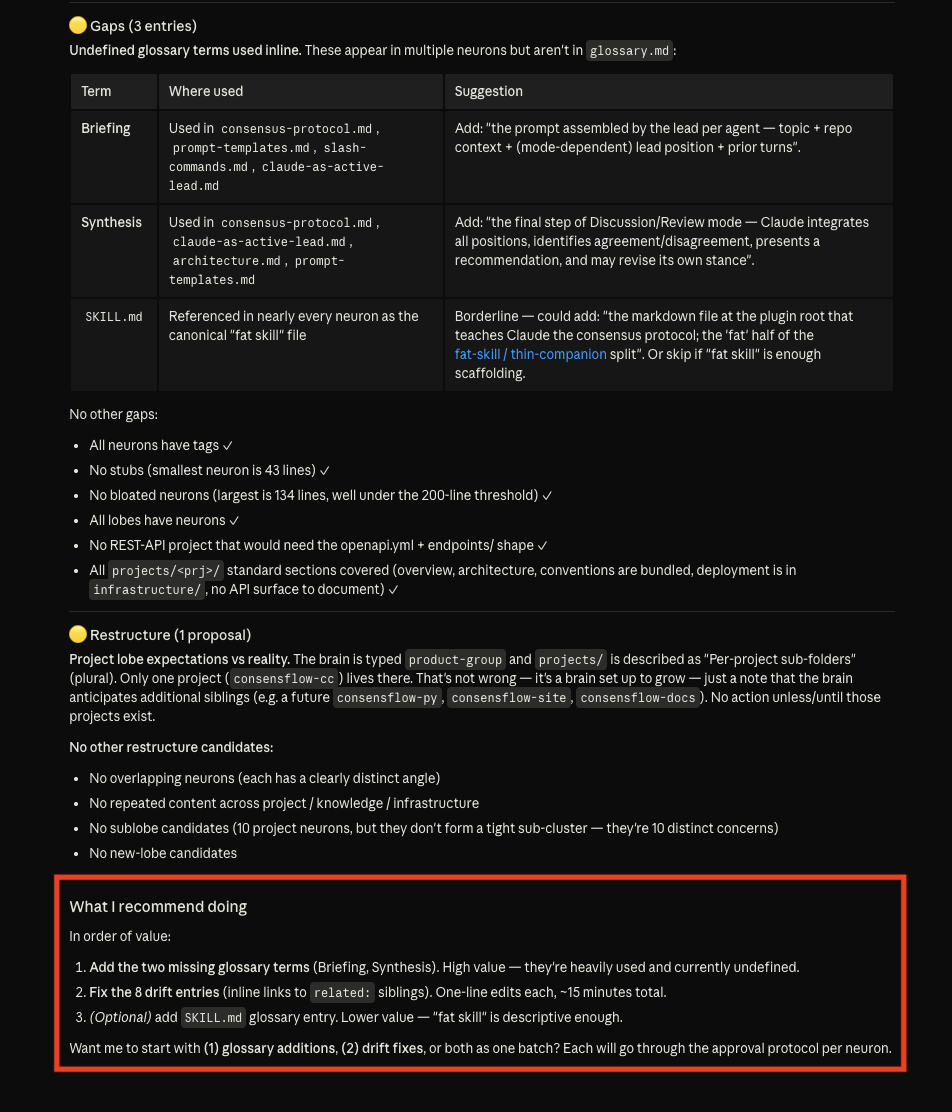
10 · The brain audits itself — gaps, missing back-references, neurons whose source files moved or vanished
11 · A mapped restructure — merge candidates, split candidates, new synapses, and a "what I recommend doing" summary
5
Phase 5 · The daily payoff
Use the brain.
Once a domain lives in the brain, every agent on every laptop reads from it before answering.
Two everyday shapes: build the next feature and
just ask — both grounded in what your team already knows.
Use case 1 · Build the next feature
Grounded coding — and grounded specs.
Tell your AI agent what to build. It reads the brain first, so it already knows your stack, your conventions,
your deploy story, your auth model — then proposes code that fits, not generic boilerplate.
Optionally, if you enabled specmint or
specmint-tdd as a companion when you created the brain, the agent can
forge a full spec from the brain first — interview, plan, implementation — every step grounded in your
team's actual knowledge.
>/kluris-acme let's add real-time presence to consensflow-cc — who's editing what→ kluris pre-flights the brain · reads projects/consensflow-cc/architecture→ reads infrastructure/realtime · reads knowledge/sessions→ proposes a plan that matches your conventions, not generic boilerplate>/kluris-acme let's create a spec for it first→ spec companion takes over (if enabled at brain creation)→ interview · plan · tasks — all written from the brain · then implement
12 · Brain pre-flight before any code is written — context loaded from neurons, then the spec workflow is launched in the terminal
Use case 2 · Just ask
Onboarding-on-tap — no more "ping the senior".
Anybody on the team types /kluris-<name> in their agent and gets the team's
actual answer — verified, git-tracked, dated, with the source neuron linked. The same questions that used to
cost a Slack ping and an interrupted senior dev now resolve in seconds, locally, in the IDE.
>/kluris-acme where is btb-backend-core deployed and how?→ reads infrastructure/deploy/coolify · cites the source neuron · dated 2026-04-12>/kluris-acme how do I deploy this to production?→ reads infrastructure/release/ghcr-pipeline · returns the exact tag-and-push flow>/kluris-acme how do I change an env variable in prod?→ reads infrastructure/secrets/coolify-env · returns the steps + who to ask before
Same shape every time: the brain reads itself, cites the neuron it answered from, and your teammate
stops being a senior-dev interrupt.
Zoom in · what the spec companion actually produces
The spec, written from the brain and the codebase — page by page.
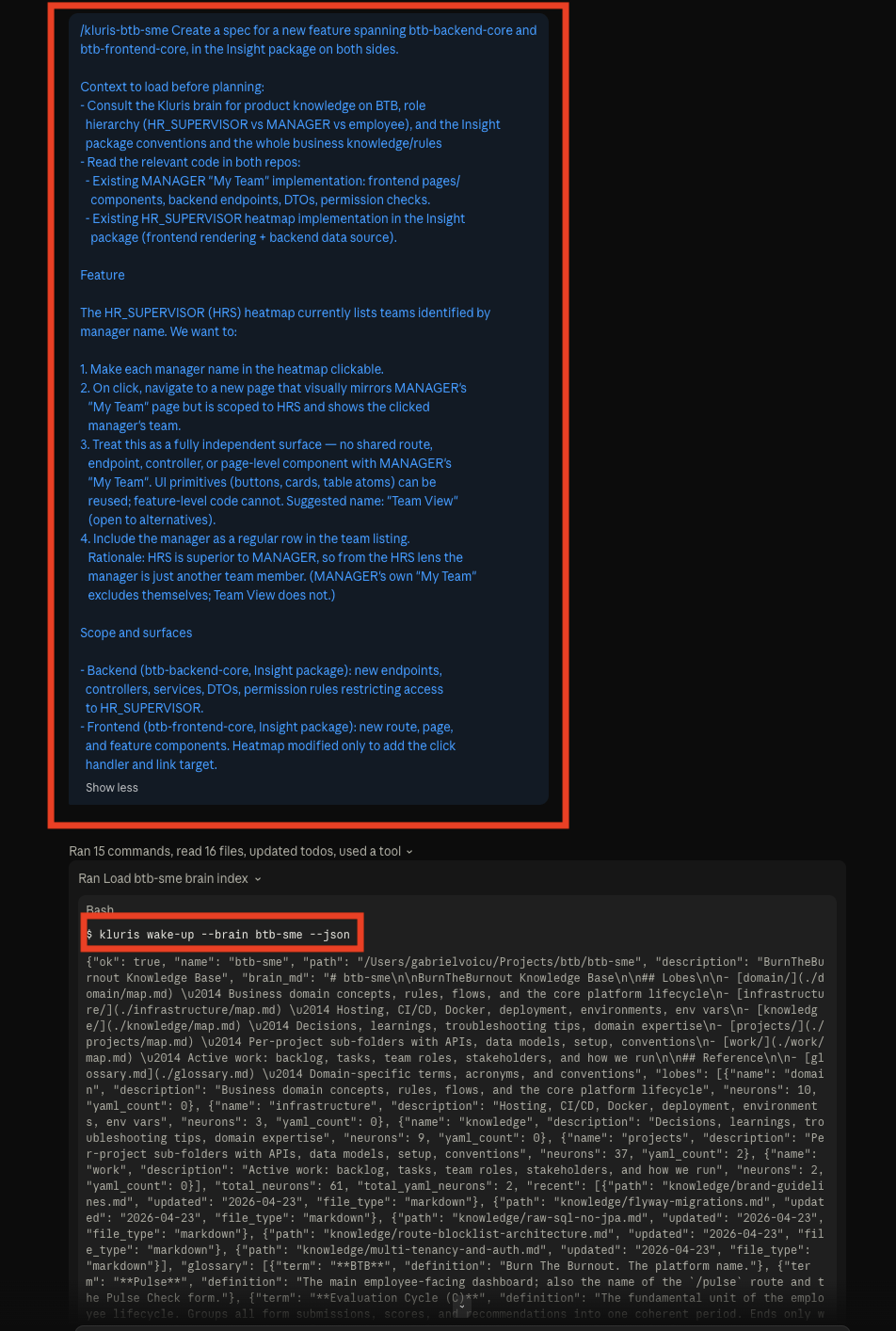
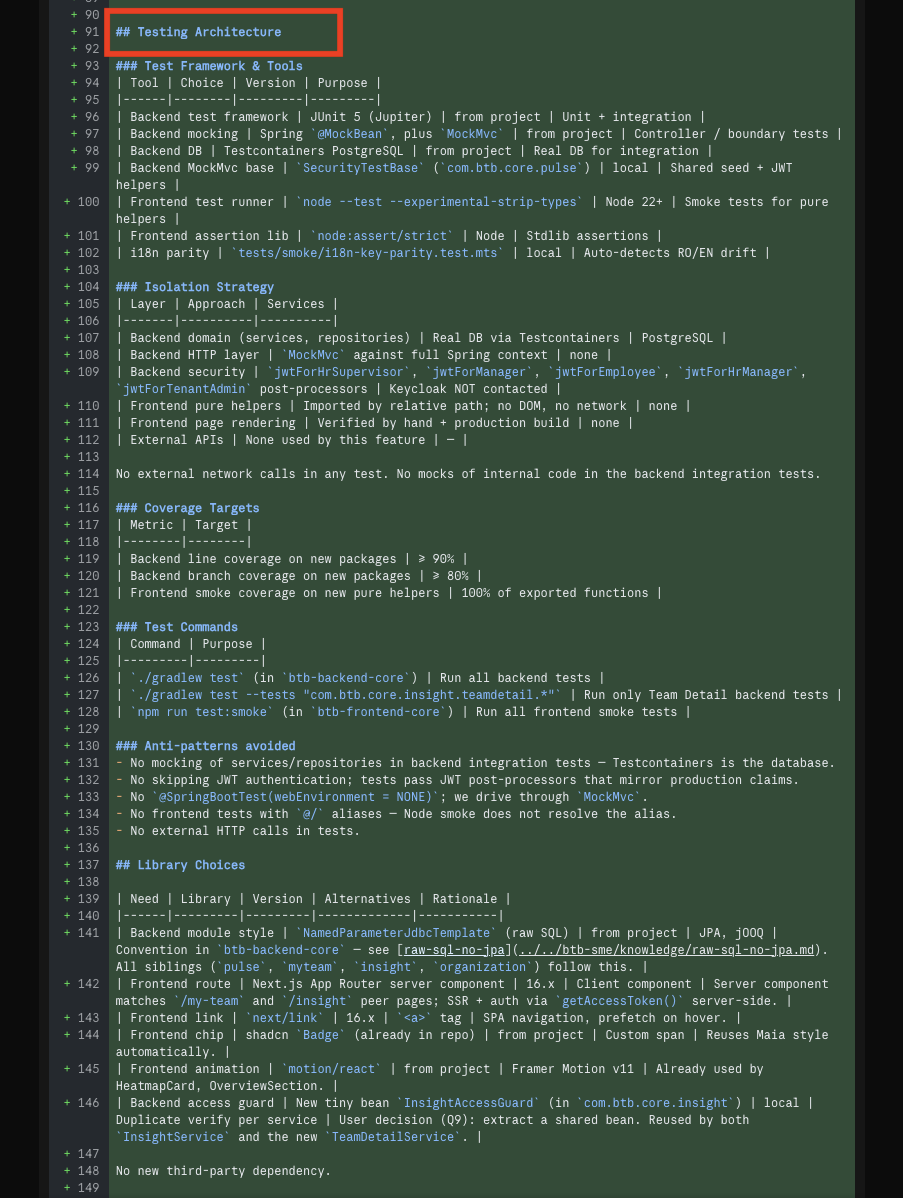
Earlier we said "if a spec companion was enabled at brain creation, it takes over." Here's what
that actually looks like — a real spec for an HR-supervisor team-detail dashboard, drafted by the agent
in minutes. Every section is grounded in two sources: the brain (decisions,
conventions, prior neurons) and the live codebase (actual files, packages, security matchers, schemas).
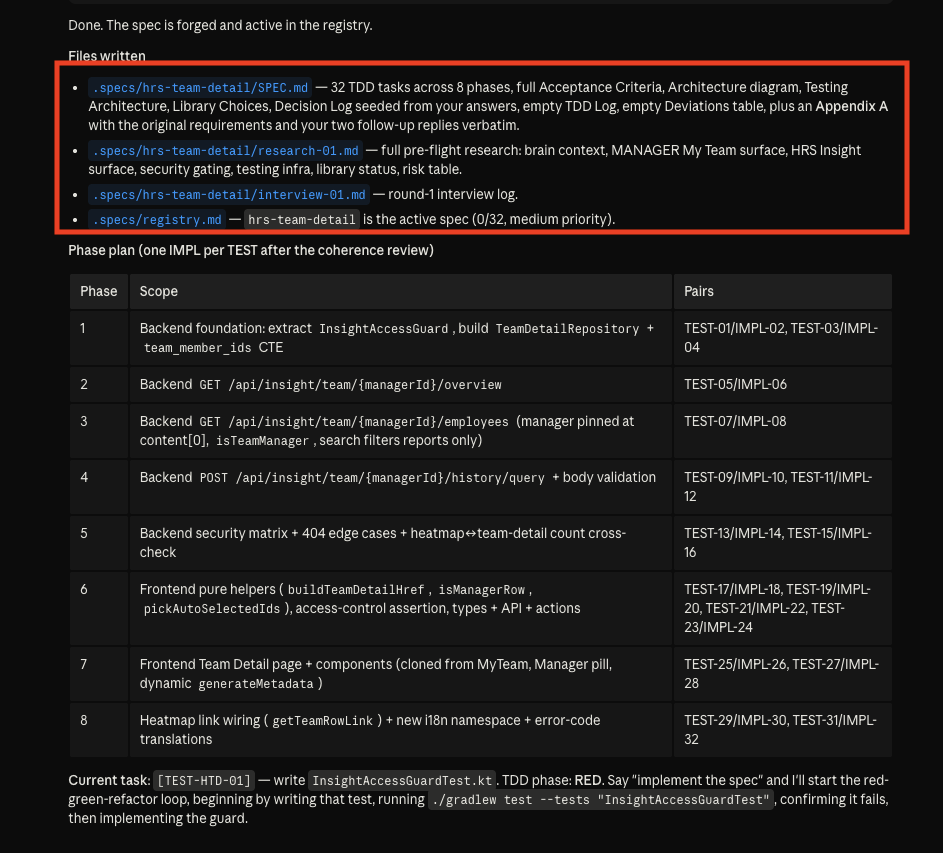
It starts with an interview to nail the ambiguity, then writes frontmatter, acceptance criteria,
architecture diagrams, phase plan, per-phase tests, alternating TEST/IMPL tasks, and a registry entry.
13 · Spec interview — the agent surfaces the open questions only you can answer before drafting
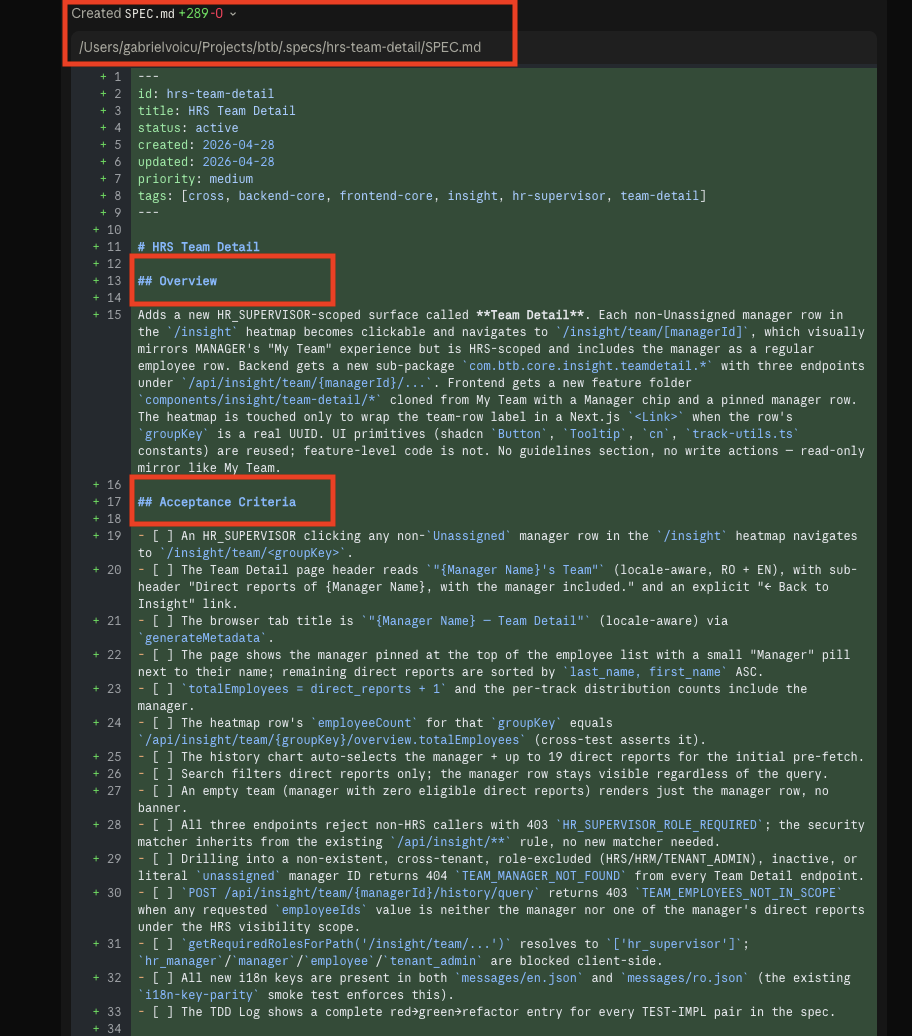
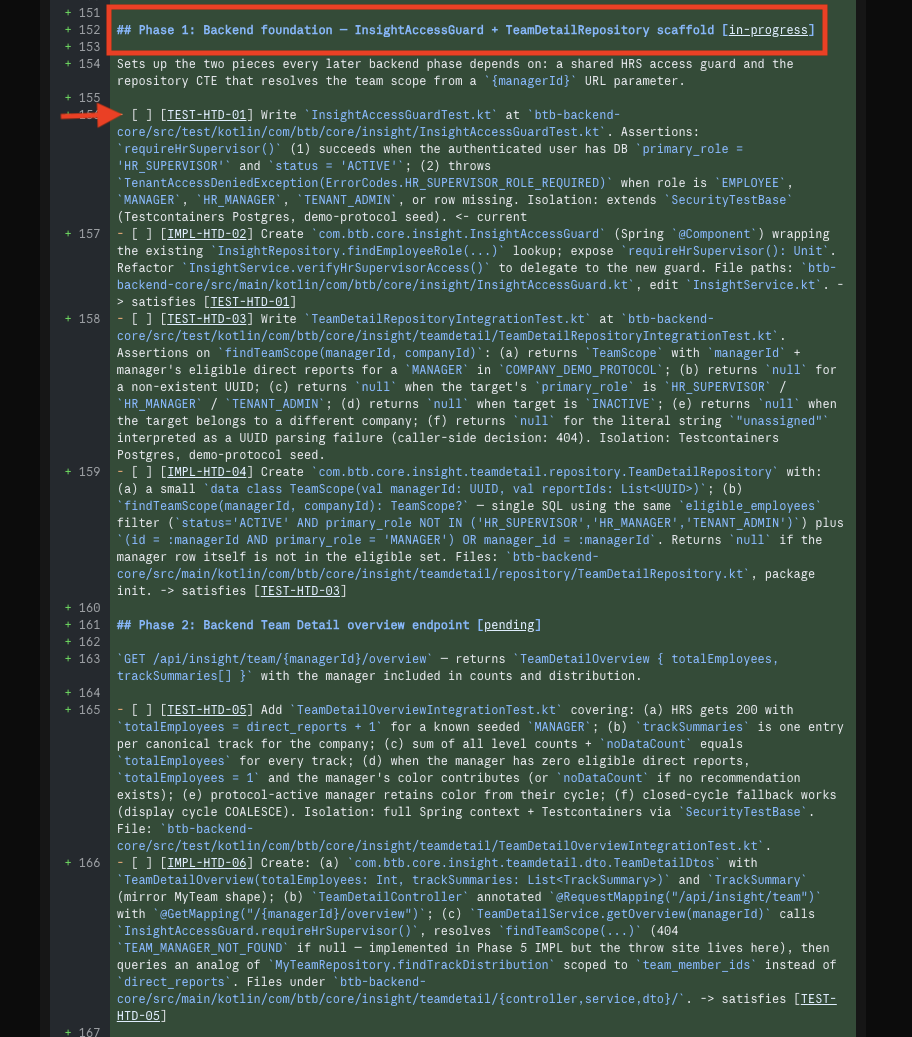
14 · The top of SPEC.md — frontmatter (id, status, owner, source, priority), the objective paragraph, and the acceptance-criteria checklist
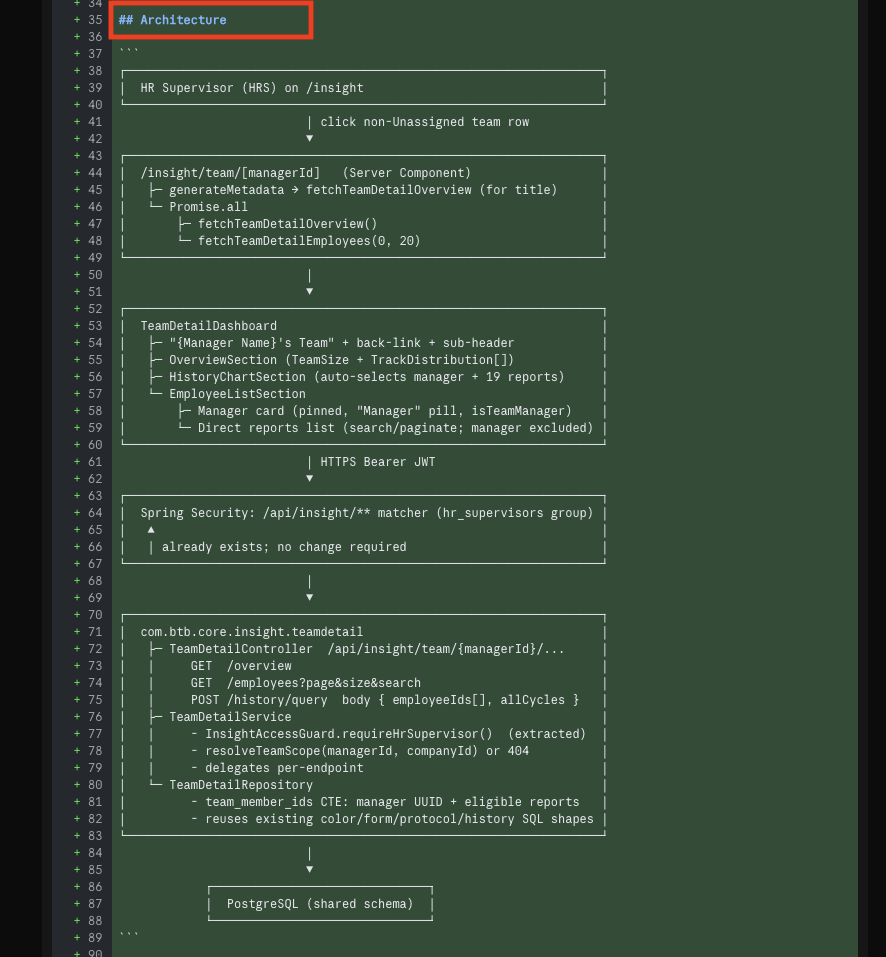
16 · The phase plan — each phase declares its own scope, tests, and exit criteria so it can ship independently
17 · Per-phase test detail — every test is named (e.g. testFetchTeamDetailOverview), with its imports and the rule it enforces spelled out
18 · The Tasks section — TEST and IMPL alternate row by row, so a failing test must exist before any code is written
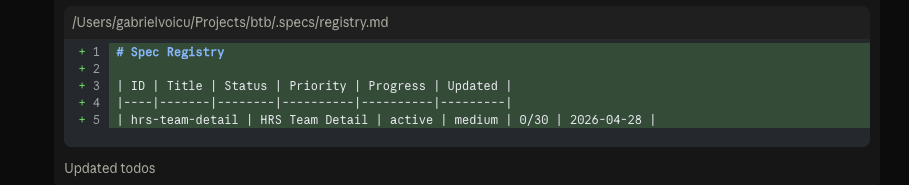
19 · A new row in .specs/registry.md — id, title, status, priority, progress, last-updated date — git-tracked for the team
20 · Implementation plan as a checklist — Phase 1 backend foundation, Phase 2 GET /overview, and so on, ready to execute test-first
Iterate · until the spec is right
Refine in place — the spec is a living document, not a one-shot artifact.
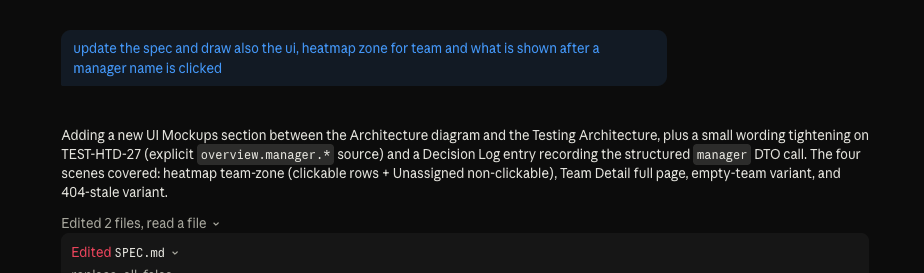
First drafts are never complete. Ask for the missing piece — UI mockups, edge cases, a clarified test, a
new decision to log — and the agent edits the spec in place. SPEC.md gets new sections, the registry
stays in sync, and every change lands as a normal git diff your team can review. Iterate as many rounds
as you need before a single line of implementation code is written.
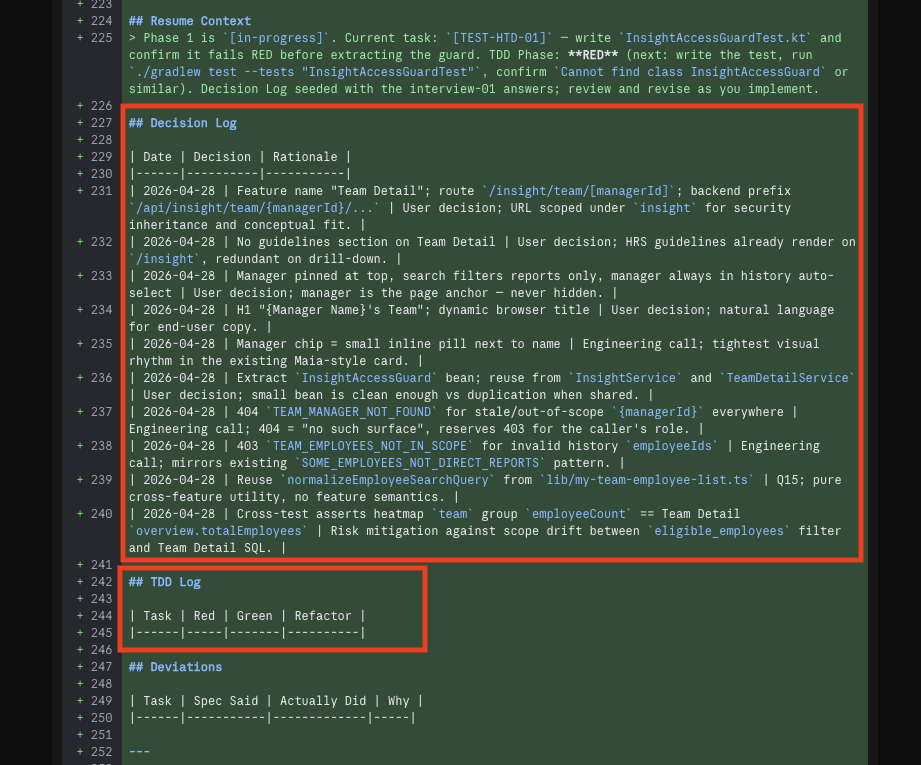
21 · Ask for what's missing ("draw the UI, heatmap zone, and the manager-click view") — the agent edits SPEC.md, tightens a test, and adds a Decision Log entry
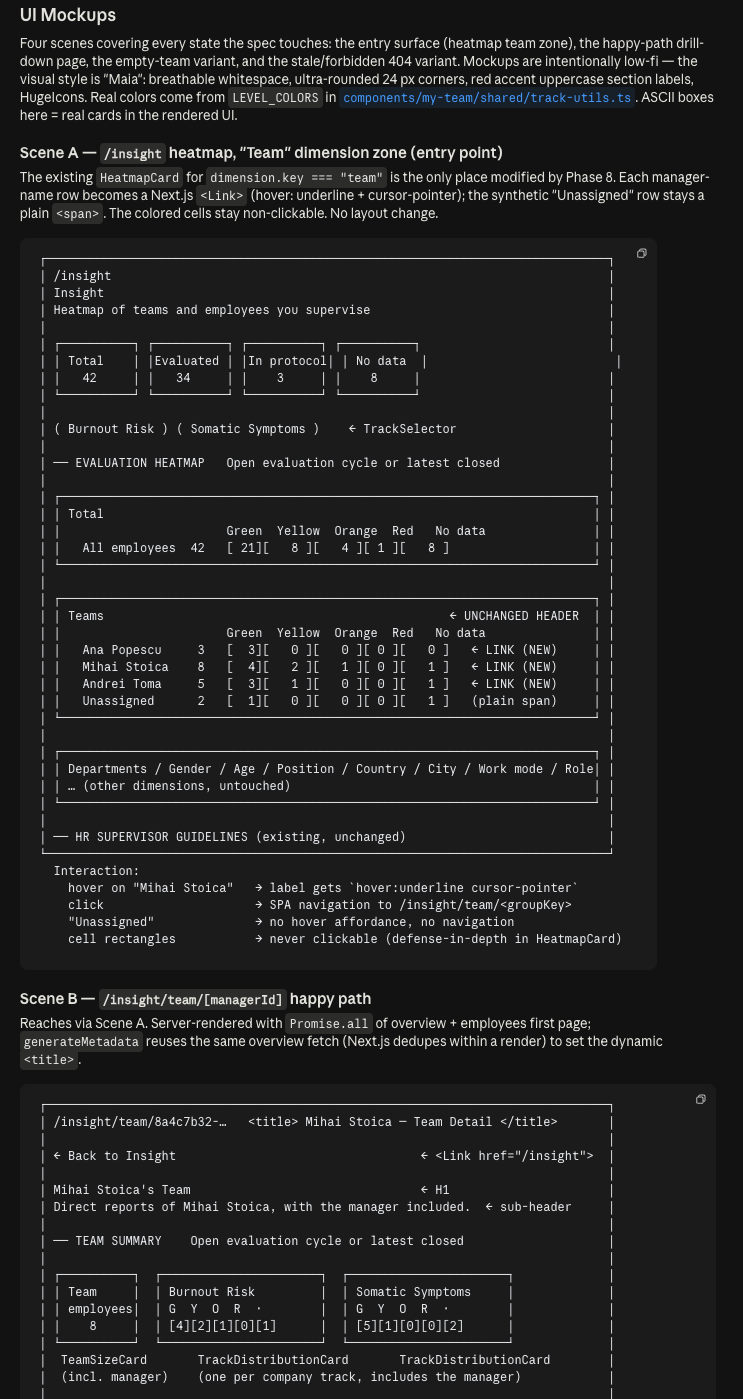
22 · The new UI Mockups section now lives in SPEC.md — four ASCII scenes: heatmap team-zone, Team Detail full page, empty-team variant, 404-stale variant
Cross-model · same brain
Write with one model. Review with another.
The /kluris-<name> skill installs into every major coding CLI — Claude Code,
Cursor, Windsurf, Codex, OpenCode, Gemini CLI, Kilo, Junie. Pick the model that fits the moment.
Draft the spec with Claude Code · Opus 4.7, then have a fresh
Codex · GPT-5.5 review it for blind spots, then ask
OpenCode running
GLM 5.1,
DeepSeek 4 Pro, or
Kimi 2.6 for a third opinion. All of them read the
same brain and the same code — you get triangulation, not silos.
Claude Code · Opus 4.7Write
>/kluris-acme let's add real-time presence to consensflow-cc — who's editing what→ kluris pre-flights the brain · reads projects/consensflow-cc/architecture→ reads infrastructure/realtime · reads knowledge/sessions>/kluris-acme let's create a spec for it first→ spec companion takes over · interview · plan · tasks→ SPEC.md drafted from brain + code · registered in .specs/registry.md
Codex · GPT-5.5Review the spec
>/kluris-acme review .specs/hrs-team-detail/SPEC.md against the brain and the codebase — challenge every assumption→ reads SPEC.md · cross-checks against brain neurons and live source files→ flags ambiguity, missing tests, conflicting decisions, weak acceptance criteria→ returns a critique with severity-ranked findings, ready to feed back into the spec
OpenCode · GLM 5.1 / DeepSeek 4 Pro / Kimi 2.6Review the code
>/kluris-acme compare the implementation in src/team-detail/ to .specs/hrs-team-detail/SPEC.md — flag drift→ reads brain · reads SPEC.md · reads the actual code · diffs intent vs reality→ returns: tasks marked done that aren't really done, missing tests, undocumented shortcuts→ a third pair of eyes from a different model family · same context, different bias
Same brain. Same code. Different model strengths. Triangulating across providers catches what a single
model — however good — would politely miss.
The loop closes · the brain compounds
After every shipped feature, ask /kluris-acme to remember what you just learned.
When the implementation is done — feature merged, bug fixed, deploy survived — turn back to the agent and ask
it to capture what you just figured out. New decisions, fresh gotchas, an updated env-var, a workaround that
took half a day to find: all of it lands in the brain as new neurons (with your approval, like always).
Tomorrow's agent reads them. Next week's teammate reads them. Next quarter's hire reads them.
>/kluris-acme remember what we worked on today and store it to the brain→ agent drafts neurons from the session: decisions, gotchas, snippets, links→ shows each one for approve · edit · reject · commits the approved ones→ git push · the whole team's brain just got smarter
That's how the brain grows: every project teaches it once, every shipped feature teaches it a little more,
and every teammate is both reader and author. Knowledge that used to live in heads, in old Slack threads,
in nobody's head — now lives in git, written by the people doing the work.
That's the whole loop
A brain that compounds with every project.
Create once · teach project by project · explore with the MRI · review periodically · use it daily for
features and answers. Every step git-tracked, every neuron human-approved, every agent on every laptop
reading the same answers tomorrow morning.