See the whole brain.
$ kluris mri MRI complete — brain-mri.html 51 neurons, 491 synapses → file:///.../brain-mri.html Open it in any browser. Commit it, email it, drop it in Slack — it runs anywhere, no server.
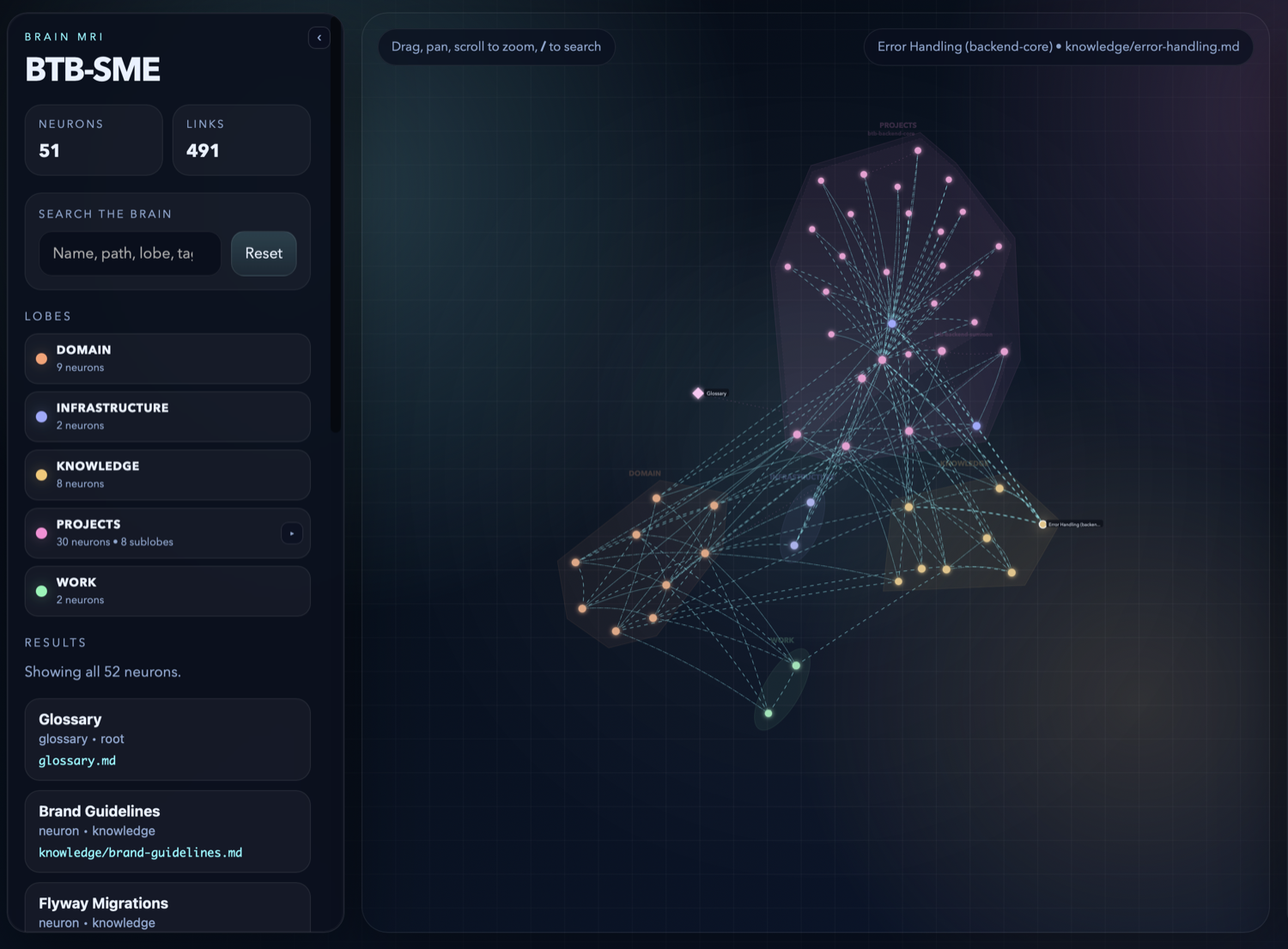
Live counts (51 neurons · 491 synapses), a lobe breakdown you can collapse and filter, and a fuzzy search across names, paths, lobes, and tags. Click a lobe to isolate it; click a node to open it.
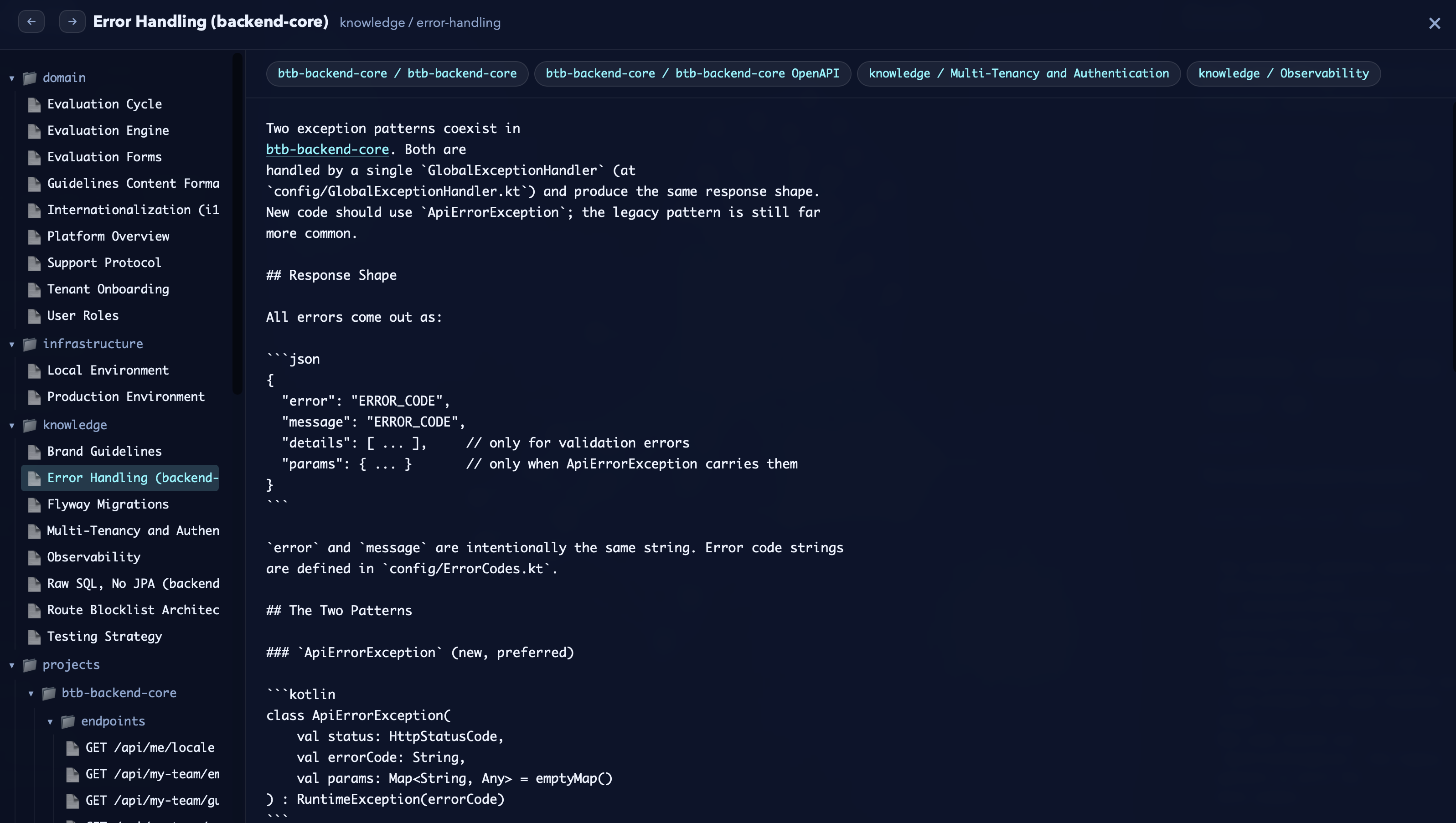
One click on any node opens its neuron, fully rendered, with the related-neuron tabs across the top so you can walk a topic in seconds. This is what agents see — now visible to you.
Lines between neurons are synapses — cross-links agents follow to load related context. A pre-digested brain means agents spend far fewer tokens orienting to a codebase than without one.
Plan with context you didn't have to re-derive.
1 · Shorter research
Forge reads your repo and consults the brain. Decisions the team already made don't get re-discovered from the code.
2 · Sharper interviews
Phase 2 stops asking what the brain already knows. Questions get surgical — the non-obvious trade-offs only you can decide.
3 · Traceable decisions
Every spec decision references a neuron. Six months later you know why — not just what — the code looks the way it does.
> /kluris-acme write a spec to add OAuth sign-in with GitHub ● Reading src/auth/ (14 files) ● Reading config/GlobalExceptionHandler.kt ← the kluris bit ● /kluris-acme what do we know about auth → knowledge/auth-decisions.md → projects/btb-core/auth-flow.md → knowledge/jwt-rotation.md Q1. Brain says you chose Keycloak for cost. Should GitHub OAuth live behind Keycloak as an IdP, or alongside it? Q2. Auth-flow neuron says refresh-at-80% TTL. Same cadence for the GitHub session? ✓ .specs/github-oauth-signin/SPEC.md ✓ 3 phases · 14 tasks · 4 decisions logged ✓ Every decision references a neuron
Enable Specmint Companions
Enable during kluris create — they ship bundled.
When the wizard asks "Install specmint companions for this brain?", answer [3] both and the companions are live the moment your brain exists.
Or add them later, per brain
specmint-core
Spec-firstResearch · Interview · Spec · Implement. The workflow shown above.
kluris companion add specmint-core
specmint-tdd
Red · Green · RefactorSame forge flow, with strict TDD — a failing test before any implementation.
kluris companion add specmint-tdd
Companions are bundled with kluris — no separate plugin install. Per brain: kluris copies only the SKILL.md and references it from the generated /kluris-<name> skill.